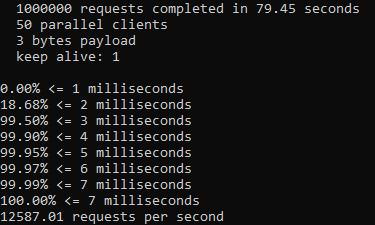
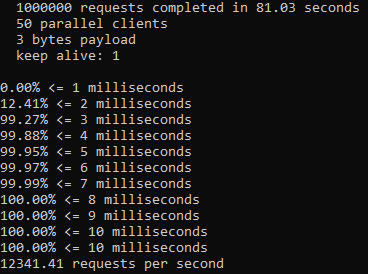
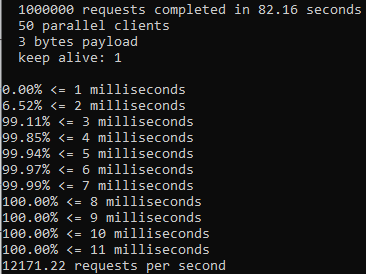
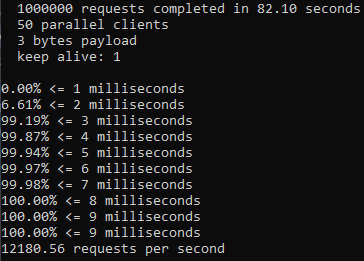
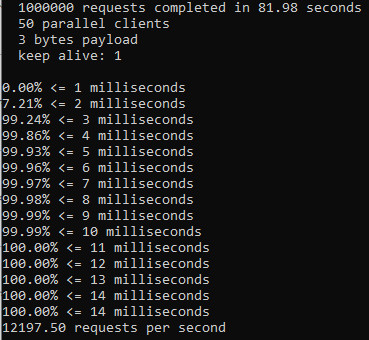
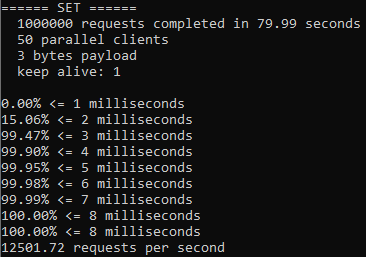
An issue was filed for Telescope to address consistency and proper use of async/await + promises and fix them. I added new linting rules. Ran an npm test:

Oh my god.
// Given 2 lists of numbers and a maximum, find the maximum of sum of a number from
// list1 + a number from list2 that is smaller or equal to the given maximum, as
// well as the number of occurrences.
function find(list1, list2, max){
let resultsArr = [];
// we will filter list2 for nums that are small or equal to given max
list2.filter((x) => {
return x <= max
})
// we will then use the filtered list and get a sum of each
.map((filteredNum) => {
list1.forEach((num) => {
resultsArr.push(num + filteredNum);
})
})
console.log(resultsArr.length)
console.log(Math.max(...resultsArr))
}
let list1 = [5,10,15]
let list2 = [1,2,3]
find(list1, list2, 2);// Given 2 lists of numbers and a maximum, find the maximum of sum of a number from
// list1 + a number from list2 that is smaller or equal to the given maximum, as
// well as the number of occurrences.
function find(list1, list2, max){
const results = []
list1.map((num1) => {
list2.forEach((num2) => {
const num = num1 + num2;
if (num <= max){
results.push(num);
}
})
})
const maxResult = Math.max(...results);
const finalResult = results.filter((num) => {
return num == maxResult;
})
console.log('The list of sums: ' + results);
console.log('The largest sum less than or equal to ' + max + ' is ' + maxResult);
console.log('The # of occurrences for the largest sum is ' + finalResult.length);
}
let list1 = [13,13,15]
let list2 = [1,2,3]
find(list1, list2, 15);









oldsize = zmalloc_size(ptr);
newptr = realloc(ptr,size);
if (!newptr) zmalloc_oom_handler(size);
update_zmalloc_stat_free(oldsize);
update_zmalloc_stat_alloc(zmalloc_size(newptr));
return newptr;oldsize = zmalloc_size(ptr); if (oldsize >= size){ memset(ptr, 0, oldsize); return ptr; } else{ newptr = realloc(ptr,size); if (!newptr) zmalloc_oom_handler(size); update_zmalloc_stat_free(oldsize); update_zmalloc_stat_alloc(zmalloc_size(newptr)); } return newptr;
const apps = includes(danger.git.fileMatchc, '../*.js');
const tests = includes(danger.git.fileMatch, '../../test/*.test.js');
if (apps.modified && !tests.modified) {
const message = `Changes were made to file in src, but not to the test file folder`;
const idea = `Perhaps check if tests for the src file needs to be changed?`;
warn(`${message} - <i>${idea}</i>`);
}
je_malloc_usable_size(JEMALLOC_USABLE_SIZE_CONST void *ptr) { size_t ret; tsdn_t *tsdn; LOG("core.malloc_usable_size.entry", "ptr: %p", ptr); assert(malloc_initialized() || IS_INITIALIZER); tsdn = tsdn_fetch(); check_entry_exit_locking(tsdn); if (unlikely(ptr == NULL)) { ret = 0; } else { if (config_debug || force_ivsalloc) { ret = ivsalloc(tsdn, ptr); assert(force_ivsalloc || ret != 0); } else { ret = isalloc(tsdn, ptr); } } check_entry_exit_locking(tsdn); LOG("core.malloc_usable_size.exit", "result: %zu", ret); return ret; }
case Blockly.NEXT_STATEMENT: {
// Don't let a block with no next connection bump other blocks out of the
// stack. But covering up a shadow block or stack of shadow blocks is
// fine. Similarly, replacing a terminal statement with another terminal
// statement is allowed.
if (candidate.isConnected() &&
!this.sourceBlock_.nextConnection &&
!candidate.targetBlock().isShadow() &&
candidate.targetBlock().nextConnection) {
return false;
}Blockly.Connection.prototype.isConnectionAllowed. The comment provided in the code perfectly explains why our orphaned end block was unable to replace the last block on the stack.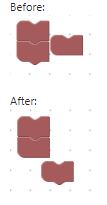

















I wrote a post roughly 2/3 years ago regarding data structures and algorithms. I thought I'd follow up with some questions I'd come...