Part3
Part 2 was to use inline assembler code, this allows assembly code to be used in C. The lines of assembly code are easily identified by __asm__.
int main() {
int a = 3;
int b = 19;
int c;
// __asm__ ("assembley code template" : outputs : inputs : clobbers)
__asm__ ("udiv %0, %1, %2" : "=r"(c) : "r"(b),"r"(a) );
__asm__ ("msub %0, %1, %2, %3" : "=r"(c) : "r"(c), "r"(a),"r"(b) );
printf("%d\n", c);
As shown in previous labs, assembly code is architecture specific. Different architectures have different instructions to carry out the same type of operations. The example above is aarch64 specific (x86_64 has a single instruction that calculates the quotient and puts the remainder in a specific register).
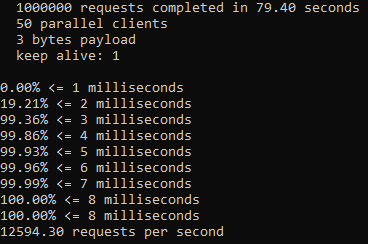
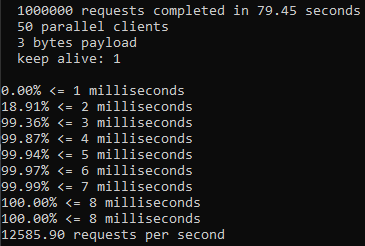
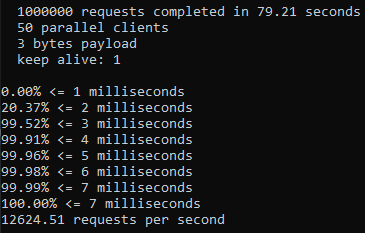
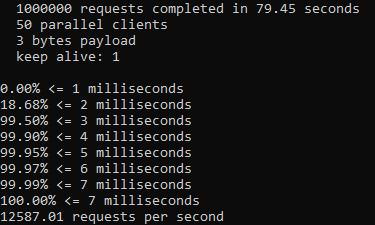
Testing with 10 million sample data

Q1.
// these variables will be used in our assembler code, so we're going
// to hand-allocate which register they are placed in
// Q: what is an alternate approach?
register int16_t* cursor asm("r20"); // input cursor
register int16_t vol_int asm("r22"); // volume as int16_t
We could do it just like the assembly code from the sample assembly code
int16_t* cursor;
int16_t vol_int;
and just use the variables with "r"(cursor) or "r"(vol_int) when we are using inline assembly instructions
Q2.
// Q: should we use 32767 or 32768 in next line? why?
vol_int = (int16_t) (0.75 * 32767.0);
I think either works, normally we'd use 32767 as that is the largest 16 bit integer. However since we are multiplying it by 0.75, using 32768 is fine.
Q3.
// Q: what does it mean to "duplicate" values in the next line?
__asm__ ("dup v1.8h,%w0"::"r"(vol_int)); // duplicate vol_int into v1.8h
The syntax for dup is DUP Vd.T, Vn.Ts[index]
The most important part here is the Vd.t where Vd is the name of the register from 0-31. T is the number of lanes we are the number of lanes we are splitting the register into 8 lanes.
Therefore we are splitting register 1 into 8 different lanes of 16 bits each and duplicating the value of vol_int into each of them.
Q4
__asm__ (
"ldr q0, [%[cursor]], #0 \n\t"
// load eight samples into q0 (v0.8h)
// from in_cursor
"sqdmulh v0.8h, v0.8h, v1.8h \n\t"
// multiply each lane in v0 by v1*2
// saturate results
// store upper 16 bits of results into
// the corresponding lane in v0
// Q: Why is #16 included in the str line
// but not in the ldr line?
"str q0, [%[cursor]],#16 \n\t"
We don't offset with the ldr because we want the whatever is in the first 16 bits of cursor to be loaded into q0. We then store whatever is in q0 into cursor before we move onto the next 16 bits in cursor's register. If we used 16 for the first line, by the end of the program we would have stored values into memory that may be for another variable.
Credits to this
site for helping me understand this whole question.
Q5
// store eight samples to [cursor]
// post-increment cursor by 16 bytes
// and store back into the pointer register
// Q: What do these next three lines do?
: [cursor]"+r"(cursor)
: "r"(cursor)
: "memory"
);
The first line is the input, second line is the output and third line is the clobber,
memory denotes the inline assembly code reads or writes to items other than those listed in the input and output.
Intrinsics
while ( cursor < limit ) {
// Q: What do these intrinsic functions do?
vst1q_s16(cursor, vqdmulhq_s16(vld1q_s16(cursor), vdupq_n_s16(vol_int)));
Using this
link as a guide.
Like the previous inline assembly, we're duplicating the value of vol_int into each of the 8 lanes, then multiplying each of them by the value of cursor and returns the high half of the truncated results. Lastly we will then store those truncated results into cursor
// Q: Why is the increment below 8 instead of 16 or some other value?
// Q: Why is this line not needed in the inline assembler version
// of this program?
cursor += 8;
}
We're only storing the high half of the truncated results which means it is only 8 bits, hence we only need to offset by 8 bits.