Release 0.4 has us similar to 0.3, except we're encouraged to contribute as much as possible to our internal repository.
This week I've been working on changing my previous test-cases to use a a library to mock responses for requests. Previously I was using my blog feed link as the parameter to send to feed parser for my tests, this test currently works as my blog is working. However if my blog was deactivated, the test will fail because the blog cannot be reached and return a false positive on the test.
By mocking the reply, I am able to always simulate my tests without having to use an actual blog feed and instead be able to use a fictional one. An actual request will be sent, however the reply will be intercepted by the library used to mock the replies. This allows me to decide what to send back as a reply such as the status and the return message.
Saturday, November 23, 2019
Tuesday, November 19, 2019
SPO600 Project Post 2
After the initial testing. I realized I was doing the benchmarking wrong. I was doing a perf report on redis-cli (tool to interact with Redis server) instead of the actual server. A proper benchmarking displayed the following:

I did a quick grep -rn 'redis-stable/' -e 'je_malloc' to find what the code looked like for the library it was using:
Now I was pretty lost, I asked the professor just what kind of optimization I can look at. I was given a few suggestions

I did a quick grep -rn 'redis-stable/' -e 'je_malloc' to find what the code looked like for the library it was using:
je_malloc_usable_size(JEMALLOC_USABLE_SIZE_CONST void *ptr) { size_t ret; tsdn_t *tsdn; LOG("core.malloc_usable_size.entry", "ptr: %p", ptr); assert(malloc_initialized() || IS_INITIALIZER); tsdn = tsdn_fetch(); check_entry_exit_locking(tsdn); if (unlikely(ptr == NULL)) { ret = 0; } else { if (config_debug || force_ivsalloc) { ret = ivsalloc(tsdn, ptr); assert(force_ivsalloc || ret != 0); } else { ret = isalloc(tsdn, ptr); } } check_entry_exit_locking(tsdn); LOG("core.malloc_usable_size.exit", "result: %zu", ret); return ret; }
Now I was pretty lost, I asked the professor just what kind of optimization I can look at. I was given a few suggestions
- check if Redis was trying to allocate new memory for set operation
- if it did, could we just overwrite the already allocated memory block for another set operation?
- check if there are a lot of deallocated memory, if there is perhaps we can allocate different size memory blocks for set operations
The function I posted above was used a lot, digging a bit deeper into the code that used the je_malloc library. I discovered it was quite complicated. Redis allows for users to define threads for operations which vastly speeds up the operations it uses.
In a perfect world, when writing data the different threads will always access different blocks of memory. However, the world is not perfect and there is a chance threads will attempt to write to the same area in memory. To avoid this, the program uses something called arenas specifically for different threads to use, to avoid stepping on each other's toes.
Memory fragmentation is also an issue, because Redis is used as a database, having data stored in memory contiguously will make get operations more efficient. jemalloc improves on malloc by trying to minimize memory fragmentation.
Thursday, November 14, 2019
Release 0.3
I recall at the beginning of the semester our professor told us sometimes during the course it is ok if we don't have a PR for an external bug as long as we're working on it. Trying to find out what's causing the bug actually takes the longest and the fix could be a change in a line or two of code. As I listened to this story, I thought "Yeah right, what are the chances of this happening to us?"
One of my goals for this course was to have a bug fix for a project from a big organization. I previously mentioned, I chose to work on a bug from Googly Blockly as it fit the bill, specifically this issue here.
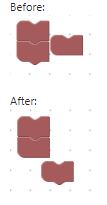 It worked! However, the quick and dirty fix may cause other issues as there was a case specifically written for this scenario, so this change will probably negatively affect other scenarios. I discussed this with @BeksOmega and asked for her opinion raising my concern and pointing out maybe the behavior which she observed that applied to rows was instead the bug.
It worked! However, the quick and dirty fix may cause other issues as there was a case specifically written for this scenario, so this change will probably negatively affect other scenarios. I discussed this with @BeksOmega and asked for her opinion raising my concern and pointing out maybe the behavior which she observed that applied to rows was instead the bug.
A person from Google eventually joined the discussion and we are waiting to hear back from another member until we decide on a way to fix this issue.
For my second internal issue, I decided to write unit tests for the feedparser function I submitted. At the time of my feedparser PR, the project didn't have any testing packages installed yet. It was fun and different as I have never written tests before, it required us to think of tests for not only normal scenarios, but for edge cases as well.
One of my goals for this course was to have a bug fix for a project from a big organization. I previously mentioned, I chose to work on a bug from Googly Blockly as it fit the bill, specifically this issue here.
Blockly is used by developers to create Blockly apps. These apps are usually for students or the public to teach coding in a beginner-friendly way.
If the issue with the link didn't provide a good overview here's a quick rundown of the issue. The person filing the bug provided some XML code to load three blocks, one stacked block of two connected blocks and one orphaned block to the right of the stack. The stacked block are pieces that can connect anywhere, whereas the orphaned block is an end piece.
I should technically be able to:
- drag the orphaned block over to the first block in the stack
- the orphaned block should replace the second block on the stack
- the current second block on the stack should be detached from the stack as it cannot connect to the new second block as it is an end piece
This is not happening, instead I am able to only connect the orphaned block to the last block in the stack and instead create a 3 stack block.
I tested each separate block in the stack and can confirm each of them can be connected to the orphaned block individually and this issue is only happening when there is a stack.
A frequent contributor to the project @BeksOmega gave me some pointers on what to look for as the main culprits:
I tested a quick and dirty fix of modifying the return false statement to return true to see if it resolved the issue:
A frequent contributor to the project @BeksOmega gave me some pointers on what to look for as the main culprits:
- a function called showPreview_ displaying a translucent preview of the result if the user was to connect the block
- a function called shouldReplace_ should be called when the user drops the block and blocks connect
- OR none of these functions get called and I have to just trace the call stack and figure out what's wrong
Guess which route I got? I spent a week tracing the call stack and identifying what each function being called did and returned.
Following the whole call stack, I finally found the culprit, the following switch statement:
case Blockly.NEXT_STATEMENT: {
// Don't let a block with no next connection bump other blocks out of the
// stack. But covering up a shadow block or stack of shadow blocks is
// fine. Similarly, replacing a terminal statement with another terminal
// statement is allowed.
if (candidate.isConnected() &&
!this.sourceBlock_.nextConnection &&
!candidate.targetBlock().isShadow() &&
candidate.targetBlock().nextConnection) {
return false;
}Blockly.Connection.prototype.isConnectionAllowed. The comment provided in the code perfectly explains why our orphaned end block was unable to replace the last block on the stack.I tested a quick and dirty fix of modifying the return false statement to return true to see if it resolved the issue:
A person from Google eventually joined the discussion and we are waiting to hear back from another member until we decide on a way to fix this issue.
For my second internal issue, I decided to write unit tests for the feedparser function I submitted. At the time of my feedparser PR, the project didn't have any testing packages installed yet. It was fun and different as I have never written tests before, it required us to think of tests for not only normal scenarios, but for edge cases as well.
Sunday, November 10, 2019
SPO600 SIMD Lab4 Pt2
Part2
What is SIMD?
Stands for Single Instruction Multiple Data, it allows parallel processing of the same operation for data. There are different sizes of registers for SIMD from 128 bits to 2048 bits and we're able to split these bits into different lanes.
We'll use a 128 bit register as an example, these are the different types of lane configurations available:
Take this for loop as an example:
int ttl = 0;
for (int x = 0; x < 100; x++){
ttl += 5;
}
We could technically speed this up by having the compiler auto-vectorize the loop because the operation is not dependent on the value of ttl as we're just adding 5 to it regardless. So we can technically run this loop in parallel with SIMD. Due to the max value of 8 bits being 255 and the value of ttl will most likely be bigger than that, the max number of lanes we should be splitting a register into is 8 so we can accommodate values up to 65536.
Even though we do split the lanes, sometimes the compiler does not auto-vectorize code:
The first point is pretty self explanatory.
The second point - if the operation being carried out in the loop was dependent on the value of its previous iteration, the loop will fail to auto-vectorize.
As part of the SIMD lab we had to change code so another loop could be auto-vectorized. We were provided the following code for the third for loop of the SIMD lab
for (x = 0; x < SAMPLES; x+=2) {
ttl = (ttl + data[x])%1000;
}
In an attempt to auto-vectorize the loop for the SIMD lab, I made the following code change:
for (x = 0; x < SAMPLES; x+=2) {
ttl += data[x]%1000;
}
The loop vectorized, the math is a little off and I wasn't able to get the same answer as the implementation of the non-vectorized one.
What is SIMD?
Stands for Single Instruction Multiple Data, it allows parallel processing of the same operation for data. There are different sizes of registers for SIMD from 128 bits to 2048 bits and we're able to split these bits into different lanes.
We'll use a 128 bit register as an example, these are the different types of lane configurations available:
- (2) 64 bit lanes
- (4) 32 bit lanes
- (8) 16 bit lanes
- (16) 8 bit lanes
Take this for loop as an example:
int ttl = 0;
for (int x = 0; x < 100; x++){
ttl += 5;
}
We could technically speed this up by having the compiler auto-vectorize the loop because the operation is not dependent on the value of ttl as we're just adding 5 to it regardless. So we can technically run this loop in parallel with SIMD. Due to the max value of 8 bits being 255 and the value of ttl will most likely be bigger than that, the max number of lanes we should be splitting a register into is 8 so we can accommodate values up to 65536.
Even though we do split the lanes, sometimes the compiler does not auto-vectorize code:
- the overhead cost of vectorization outweighs the benefit of vectorization
- loops must not overlap in a way that is affected by vectorization
The first point is pretty self explanatory.
The second point - if the operation being carried out in the loop was dependent on the value of its previous iteration, the loop will fail to auto-vectorize.
As part of the SIMD lab we had to change code so another loop could be auto-vectorized. We were provided the following code for the third for loop of the SIMD lab
for (x = 0; x < SAMPLES; x+=2) {
ttl = (ttl + data[x])%1000;
}
In an attempt to auto-vectorize the loop for the SIMD lab, I made the following code change:
for (x = 0; x < SAMPLES; x+=2) {
ttl += data[x]%1000;
}
The loop vectorized, the math is a little off and I wasn't able to get the same answer as the implementation of the non-vectorized one.
SPO600 Project Selection
In an attempt to learn more about the backend we're using as part of our OSD600 internal project and to make contributions to a widely used open source project, I decided to optimize Redis as my SPO600 project.
First I had to create some data:
for ((x=0; x<100; x++)) ; do echo "$(dd if=/dev/urandom | tr -d -c "a-z" | dd bs=15 count=1 2>/dev/null)=$(dd if=/dev/urandom | tr -d -c "a-z" | dd bs=10 count=1 2>/dev/null)" | cat >> testData ; done
this block of of code will run a for loop 100 times
within the loop:
First I had to create some data:
for ((x=0; x<100; x++)) ; do echo "$(dd if=/dev/urandom | tr -d -c "a-z" | dd bs=15 count=1 2>/dev/null)=$(dd if=/dev/urandom | tr -d -c "a-z" | dd bs=10 count=1 2>/dev/null)" | cat >> testData ; done
this block of of code will run a for loop 100 times
within the loop:
- output to the screen randomly generated key(15 chars) value(10 chars) pairs made up of lower case letters
- .take whatever is outputted on the screen and append to a file called testData
At the moment I can run a perf record with the following bash line
perf record redis-cli set foo bar
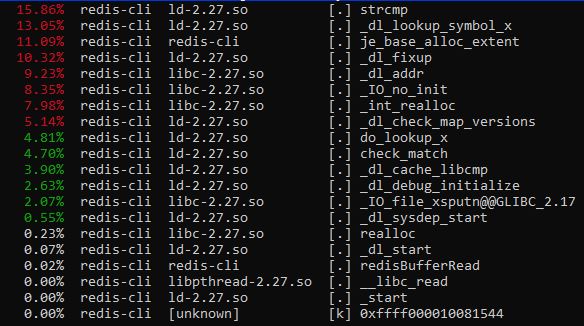


- this allows me to do a sampling of the command set foo far
which generates the following report:

Upon further research, Redis actually comes with its own benchmarking tool called redis-benchmark. A great source of documentation published on DigitalOcean can be found here.
An example of a command I ran:
redis-benchmark -t set -n 10000
A simple breakdown of the command
- redis-benchmark - the command
- -t (command)- use a subset of tests specified by command, in this case I'm using set
- -n (number of requests)- number of commands to carry out

The tool is useful because it allows me to track how many seconds it took to complete each operation for x amount of requests, which in this case it to set 10000 key value pairs.
The command also allows users to specify how big each randomly generated block size (for the key/value pairs) should be(default 3), to ensure consistency between operations. I also am not only limited to just benchmarking the set only, I can specify in the CLI set,get and redis-benchmark will then also benchmark how long it took to get x amount of values.

Friday, November 8, 2019
Open Source November Edition
October, Hacktoberfest is finished and we're moving onwards!
Our task for November is to experiment with different technologies and revamp the CDOT Planet Feed between the professor's two open source classes. The project is called Telescope and is intended to be written in Javascript for as long as technically possible. My issue for the project this week was to create a parser to parse either a RSS or Atom feed.
With some discussion and suggestions from @ImmutableBox, @lucacataldo and our professor @humphd. I managed to finally write one with the following
const parsefeeder = require('parsefeeder-promised')
module.exports = async function (feed) {
return parsefeeder.parse(feed);
};
Ironically these few lines took a few days. We tried to avoid using the npm package shown and tried to write it from scratch using bent and feedparser. We realized it was kind of impossible to return the data we wanted, and finally resorted to using the feedparser-promised package suggested by @lucacataldo. Feel free to read about the internal discussion of my pull request for the issue here.
For an external bug as part of release 0.3, I chose to work on Googly Blockly, specifically this issue here.
Our task for November is to experiment with different technologies and revamp the CDOT Planet Feed between the professor's two open source classes. The project is called Telescope and is intended to be written in Javascript for as long as technically possible. My issue for the project this week was to create a parser to parse either a RSS or Atom feed.
With some discussion and suggestions from @ImmutableBox, @lucacataldo and our professor @humphd. I managed to finally write one with the following
const parsefeeder = require('parsefeeder-promised')
module.exports = async function (feed) {
return parsefeeder.parse(feed);
};
Ironically these few lines took a few days. We tried to avoid using the npm package shown and tried to write it from scratch using bent and feedparser. We realized it was kind of impossible to return the data we wanted, and finally resorted to using the feedparser-promised package suggested by @lucacataldo. Feel free to read about the internal discussion of my pull request for the issue here.
For an external bug as part of release 0.3, I chose to work on Googly Blockly, specifically this issue here.
Wednesday, November 6, 2019
SPO600 SIMD Lab4 Pt3
Part3
Part 2 was to use inline assembler code, this allows assembly code to be used in C. The lines of assembly code are easily identified by __asm__.
int main() {
int a = 3;
int b = 19;
int c;
// __asm__ ("assembley code template" : outputs : inputs : clobbers)
__asm__ ("udiv %0, %1, %2" : "=r"(c) : "r"(b),"r"(a) );
__asm__ ("msub %0, %1, %2, %3" : "=r"(c) : "r"(c), "r"(a),"r"(b) );
printf("%d\n", c);
As shown in previous labs, assembly code is architecture specific. Different architectures have different instructions to carry out the same type of operations. The example above is aarch64 specific (x86_64 has a single instruction that calculates the quotient and puts the remainder in a specific register).
Testing with 10 million sample data

Q1.
// these variables will be used in our assembler code, so we're going
// to hand-allocate which register they are placed in
// Q: what is an alternate approach?
register int16_t* cursor asm("r20"); // input cursor
register int16_t vol_int asm("r22"); // volume as int16_t
We could do it just like the assembly code from the sample assembly code
int16_t* cursor;
int16_t vol_int;
and just use the variables with "r"(cursor) or "r"(vol_int) when we are using inline assembly instructions
Q2.
// Q: should we use 32767 or 32768 in next line? why?
vol_int = (int16_t) (0.75 * 32767.0);
I think either works, normally we'd use 32767 as that is the largest 16 bit integer. However since we are multiplying it by 0.75, using 32768 is fine.
Q3.
// Q: what does it mean to "duplicate" values in the next line?
__asm__ ("dup v1.8h,%w0"::"r"(vol_int)); // duplicate vol_int into v1.8h
The syntax for dup is DUP Vd.T, Vn.Ts[index]
The most important part here is the Vd.t where Vd is the name of the register from 0-31. T is the number of lanes we are the number of lanes we are splitting the register into 8 lanes.
Therefore we are splitting register 1 into 8 different lanes of 16 bits each and duplicating the value of vol_int into each of them.
Q4
__asm__ (
"ldr q0, [%[cursor]], #0 \n\t"
// load eight samples into q0 (v0.8h)
// from in_cursor
"sqdmulh v0.8h, v0.8h, v1.8h \n\t"
// multiply each lane in v0 by v1*2
// saturate results
// store upper 16 bits of results into
// the corresponding lane in v0
// Q: Why is #16 included in the str line
// but not in the ldr line?
"str q0, [%[cursor]],#16 \n\t"
We don't offset with the ldr because we want the whatever is in the first 16 bits of cursor to be loaded into q0. We then store whatever is in q0 into cursor before we move onto the next 16 bits in cursor's register. If we used 16 for the first line, by the end of the program we would have stored values into memory that may be for another variable.
Credits to this site for helping me understand this whole question.
Q5
// store eight samples to [cursor]
// post-increment cursor by 16 bytes
// and store back into the pointer register
// Q: What do these next three lines do?
: [cursor]"+r"(cursor)
: "r"(cursor)
: "memory"
);
The first line is the input, second line is the output and third line is the clobber, memory denotes the inline assembly code reads or writes to items other than those listed in the input and output.
Intrinsics
while ( cursor < limit ) {
// Q: What do these intrinsic functions do?
vst1q_s16(cursor, vqdmulhq_s16(vld1q_s16(cursor), vdupq_n_s16(vol_int)));
Using this link as a guide.
Like the previous inline assembly, we're duplicating the value of vol_int into each of the 8 lanes, then multiplying each of them by the value of cursor and returns the high half of the truncated results. Lastly we will then store those truncated results into cursor
// Q: Why is the increment below 8 instead of 16 or some other value?
// Q: Why is this line not needed in the inline assembler version
// of this program?
cursor += 8;
}
We're only storing the high half of the truncated results which means it is only 8 bits, hence we only need to offset by 8 bits.
Tuesday, November 5, 2019
SPO600 Lab4 (Algorithm Selection) Continued
Building on top of the previous post, the second task of the lab was to create a look-up table with all the samples already scaled.
Refer to the code below to see some changes to the original code:
// since we can't use negative index we start at the lowest value
int16_t val = -32768;
// create and populate array with scaled sample values
for (int i = 0; i < size; i++){
lookupTable[i] = scale_sample(val, 0.75);
val++;
}
// Allocate memory for large in and out arrays
int16_t* data;
data = (int16_t*) calloc(SAMPLES, sizeof(int16_t));
int x;
int ttl = 0;
// Seed the pseudo-random number generator
srand(1);
// Fill the array with random data
for (x = 0; x < SAMPLES; x++) {
data[x] = (rand()%65536)-32768;
}
// ######################################
// This is the interesting part!
// Scale the volume of all of the samples
for (x = 0; x < SAMPLES; x++) {
//need to add 32768 so we don't get a negative index
data[x] = lookupTable[(data[x]+32768)];
}
Overall, it was weird. I expected it to be faster, I even gave it an edge by doubling the number of samples to 10 million instead of the original 5 million.

A perf report of vol2 shows 0.05% of the time was spent scaling the sample.



Refer to the code below to see some changes to the original code:
// since we can't use negative index we start at the lowest value
int16_t val = -32768;
// create and populate array with scaled sample values
for (int i = 0; i < size; i++){
lookupTable[i] = scale_sample(val, 0.75);
val++;
}
// Allocate memory for large in and out arrays
int16_t* data;
data = (int16_t*) calloc(SAMPLES, sizeof(int16_t));
int x;
int ttl = 0;
// Seed the pseudo-random number generator
srand(1);
// Fill the array with random data
for (x = 0; x < SAMPLES; x++) {
data[x] = (rand()%65536)-32768;
}
// ######################################
// This is the interesting part!
// Scale the volume of all of the samples
for (x = 0; x < SAMPLES; x++) {
//need to add 32768 so we don't get a negative index
data[x] = lookupTable[(data[x]+32768)];
}
Overall, it was weird. I expected it to be faster, I even gave it an edge by doubling the number of samples to 10 million instead of the original 5 million.


The original for reference with 10 million samples

A perf report of vol1 is also shown below

Sunday, November 3, 2019
SPO600 Compiler Optimizations
As we start our projects for SPO600, the professor introduced the class to optimizations the compiler does automatically for code, so we don't try to do similar ones manually. I'll explain a few ones as it was interesting (at least to me) what types of things are done behind the scenes make code more efficient.
Hoisting
Some times code written in a loop is the same no matter the iteration. For example
//Increments i by k
int k;
for (int i = 0; i < 10; i++){
k = 5 + 9;
i += k;
}
Since the value of k is 14 no matter how many times the loop is run. The compiler figures it can move the line k = 5+9; outside of the loop so we get something like the the below
//Increments i by k
int k;
k = 5 + 9;
for (int i = 0; i < 10; i++){
i += k;
}
This shaves off a bit of computing time because now k doesn't have to compute the value of k for
i < 10 times.
Dead Store
This sometimes happens in code, a variable assigned a value, is assigned another one before it is used. For example
//Increments i by k
int k;
k = 0;
k = 5 + 9;
for (int i = 0; i < 10; i++){
i += k;
}
As you noticed, k = 0; is never used and is reassigned to 5 + 9; The compiler notices this when it does an internal representation of the code and will remove k = 0 so the code becomes
//Increments i by k
int k;
k = 5 + 9;
for (int i = 0; i < 10; i++){
i += k;
}
Strength Reduction
Multiplication and division in code is more expensive than adding or subtracting. Take the following for example
//Multiplies i by k
int k = 5;
for (int i = 0; i < 10; i++){
int c = k * i;
printf(c);
}
The compiler will do something like the below:
//Multiplies i by k
int k = 5;
for (int i = 0; i < 50; i+=5){
int c = k + i;
printf(c);
}
Both programs will output 0, 5, 10... up until 50. However the multiplication operation has now been swapped out for an addition operation.
Hoisting
Some times code written in a loop is the same no matter the iteration. For example
//Increments i by k
int k;
for (int i = 0; i < 10; i++){
k = 5 + 9;
i += k;
}
Since the value of k is 14 no matter how many times the loop is run. The compiler figures it can move the line k = 5+9; outside of the loop so we get something like the the below
//Increments i by k
int k;
k = 5 + 9;
for (int i = 0; i < 10; i++){
i += k;
}
This shaves off a bit of computing time because now k doesn't have to compute the value of k for
i < 10 times.
Dead Store
This sometimes happens in code, a variable assigned a value, is assigned another one before it is used. For example
//Increments i by k
int k;
k = 0;
k = 5 + 9;
for (int i = 0; i < 10; i++){
i += k;
}
As you noticed, k = 0; is never used and is reassigned to 5 + 9; The compiler notices this when it does an internal representation of the code and will remove k = 0 so the code becomes
//Increments i by k
int k;
k = 5 + 9;
for (int i = 0; i < 10; i++){
i += k;
}
Strength Reduction
Multiplication and division in code is more expensive than adding or subtracting. Take the following for example
//Multiplies i by k
int k = 5;
for (int i = 0; i < 10; i++){
int c = k * i;
printf(c);
}
The compiler will do something like the below:
//Multiplies i by k
int k = 5;
for (int i = 0; i < 50; i+=5){
int c = k + i;
printf(c);
}
Both programs will output 0, 5, 10... up until 50. However the multiplication operation has now been swapped out for an addition operation.
Subscribe to:
Posts (Atom)
Contains Duplicate (Leetcode)
I wrote a post roughly 2/3 years ago regarding data structures and algorithms. I thought I'd follow up with some questions I'd come...
-
 I wrote a post roughly 2/3 years ago regarding data structures and algorithms. I thought I'd follow up with some questions I'd come...
I wrote a post roughly 2/3 years ago regarding data structures and algorithms. I thought I'd follow up with some questions I'd come... -
Ever since I've enrolled in the Open Source Development classes at Seneca, I've had a blast. I learned about using all sorts of new ...